Until the birth of OCR that recognizes text (Upstage in-house OCR image data collection challenge)
02/21/2023 | 3mins
-
Haley (Content Communication)
-
Anyone who wants to know about OCR and Document AI
THOSE WHO ARE CURIOUS ABOUT UPSTAGE OCR TECHNOLOGY
-
Do you know about OCR technology, which is being used for digital innovation in various industries by recognizing letters in captured images? We introduce the story of the in-house OCR image data collection challenge in which stars worked as one team to collect data for model training and laid the foundation for performance until the creation of Upstage Document AI, which enabled document automation without human post-processing.
-
✔️ Background and purpose of the in-house image data collection event
✔️ Images to collect
✔️ Critical data for high-accuracy model implementation
✔️ Data gathered by events
✔️ Effects of in-house image data collection events
✔️ Upstage data team plans and aspirations
Upstage recently signed a contract with Hanwha Life Insurance to supply 'Document AI', an optical character recognition solution ! Upstage's no-code-low-code AI solution 'Document AI', which efficiently processes five types of insurance claim documents, including medical expense receipts, was introduced to the industry for the first time, taking the lead in AI innovation in the financial sector. Until the development of Document AI , Upstage stars worked as a team to create the highest performance solution . In the process, we held an in-house image data collection event for OCR model training and took on the challenge of collecting image data with stars working together.
Thanks to many efforts, Upstage's Document AI has achieved an incredible recognition rate of over 95% accuracy with basic model performance alone, enabling document automation without human post-processing . We looked back on last year's in-house image data collection challenge, which became the cornerstone of the creation of Document AI, through an interview with Upstage's data manager, Hyeon Joo .
[ See the highest performance AI OCR, Upstage Document AI → ]
In-house image data collection event
What is the background and purpose of opening it?
Upstage is creating and servicing ' Document AI ', an OCR (Optical Character Recognition) model specialized for Korean and English. OCR is a technology that is used for digital innovation in various industries by detecting and recognizing text areas in captured images.
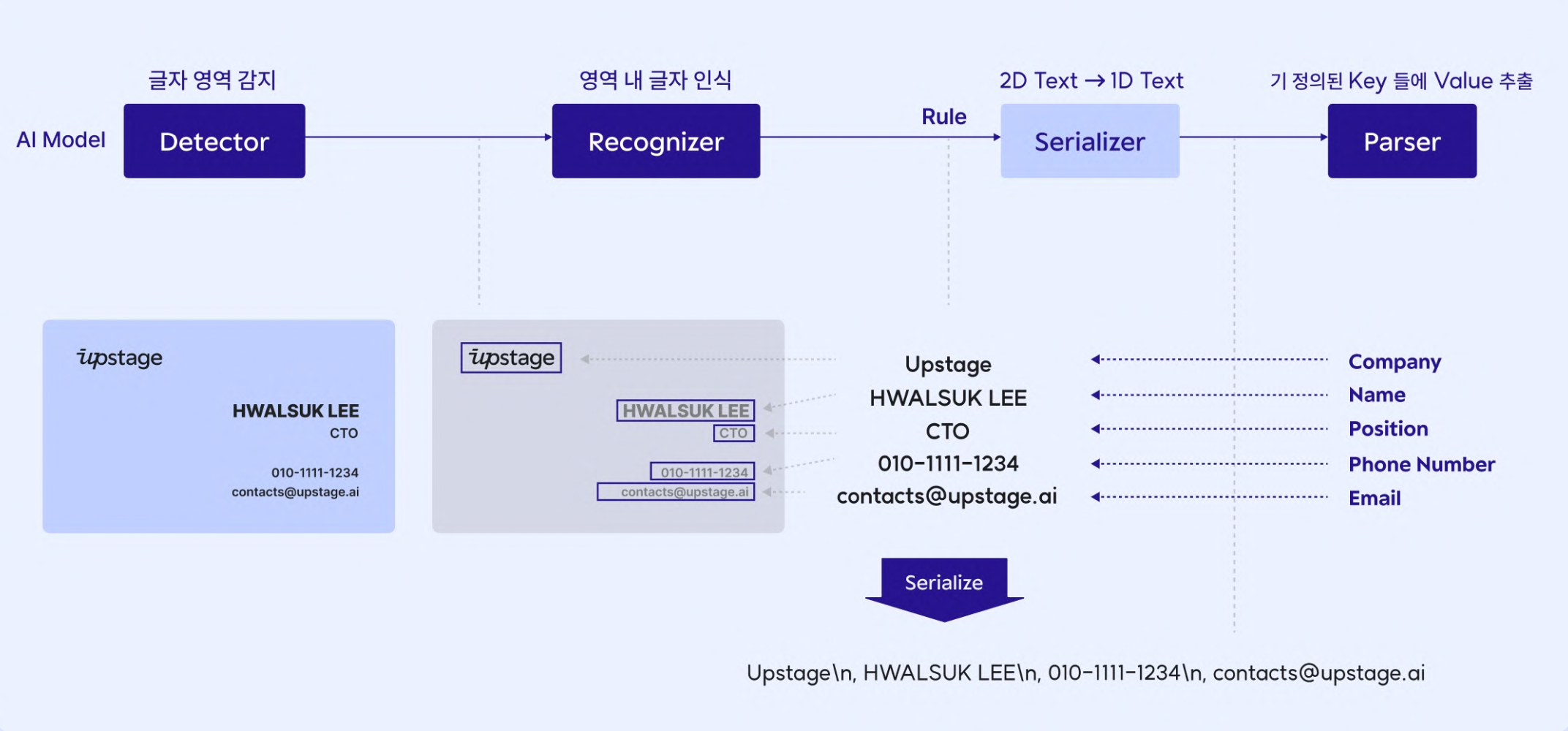
Description of Optical Character Recognition (OCR) technology
In order to create this model , a process of learning the model through a large amount of data is required. In addition to the public data we used to use, we need many additional parts, so we planned an in-house image data collection event to collect data that can be used here. Scores were given according to the characteristics of the images, and a small amount of prizes were given to the Top 3 and 2 random people so that more people could participate happily.
In particular, the second in-house image data collection event held in March collected many special cases such as vertical and handwriting in addition to scene text (horizontal text, signboards, book contents, etc.) It started with the intention of wanting to develop it further.
What images were you collecting?
You can take and submit photos containing subjects that contain Korean or Roman characters (alphabet-based characters) . In particular, for the training of a robust model, we considered good data to have various font sizes, shapes (fonts), angles, etc., and divided the points according to the characteristics of the images submitted. Considering the characteristics that the existing model of Upstage was vulnerable to, additional points were given for vertical writing, handwriting, embossed engraving, letters composed of dot/line combinations such as electric signs or digital clocks, and violations of letter boundaries such as underlines or highlighters. .



Examples of vertical writing, handwriting, and embossed writing from the left
In addition, we opened the demo site of our OCR model to find out what images the current model has difficulty with, and if stars upload images directly to the demo site, they can check the prediction results of the model, so that you can participate in it with fun.

UPSTAGE OCR DEMO SITE USED AS A REFERENCE FOR SUBMITTING AN IN-HOUSE IMAGE DATA COLLECTION EVENT
You have heard the importance of data for AI model training.
How much data do you need to implement a high-fidelity model?
Depending on the accuracy you are aiming for, the amount of data you need may vary. In the case of general scene text data, it takes about 50,000 pieces of data to train the model to be quite usable when viewed by humans. Of course, the more learning data we have, the better, so we tried to collect as much image data as possible through in-house events.
How much data was gathered through the event?
Thanks to the participation of many stars as a team, a total of 7,570 image data was additionally collected. The glory of Top 2 high scorers went to Van (4.326 points) and Yujeong (3.373 points). In particular, it is memorable that Van, who won first place, passionately participated in the event through various strategies. I heard that you went to a bookstore where you can secure a large amount of vertical writing images by focusing on items that give extra points . Through the pictures of the titles of the books on the bookshelf, you got a high bonus score in the vertical writing category.
In addition, a leaderboard was operated to check the scores of individual submitted images, and since this was updated every 30 minutes, it was said that the game of notice was fierce for the top ranks until the deadline. I was also able to hear an interesting back story about the high-level strategy that the final result was not noticeable by submitting the image right before the deadline.

Submission example of a star who won 1st place in an in-house image data collection event (vertical writing)
What effects did you get from the in-house image data collection event?
Since the performance of a model varies depending on the test set or measurement method, it is difficult to compare, for example, when performance improves in one domain, performance deteriorates in another domain. However, when the data collected through this in-house event was additionally used , I was surprised that the performance improved significantly in all domains.
In particular, one of the main achievements obtained through the event was that we were able to quantitatively check model issues by intensively collecting images of poor model performance, such as handwriting or unusual style handwriting . In the meantime, there was not enough training data except for the test set to identify issues, so until we gathered enough training data, we had no choice but to approach the performance of the model from an empirical point of view. However, we were able to collect a lot of image data for training through in-house events, and thanks to this, we were able to quantitatively measure test set configuration or model issues for special cases.
In this event, scene text was collected to improve the performance of our general-purpose OCR model , and the shape, size, and characteristics of characters are different compared to document text, which is somewhat standardized. I think this gives me the basic skills to develop into various other tasks later.
The OCR model recently supplied to Hanwha Life Insurance is specialized for documents, so it is a different area from the general-purpose OCR model. However, in the early days of Upstage Document AI development, rather than building a model that focused on only one thing, we decided to create a model with the basics. I think setting our own hypotheses and goals served as a good stepping stone.
The Data Team is a strong pillar of Upstage OCR!
I am curious about your future plans and aspirations.
Our data team's goal this year is to supply the data needed for engine development in a timely manner .
Since there is a lot of collaboration with the Document AI Engine team, we are working hard to create good data that can solve challenges together. For example, we would like to focus on improving the recognition performance of things such as handwriting, check boxes, and stamps in documents required for the document specialized model that we have been focusing on recently. In order to provide such diverse data in a timely manner, we are considering the aspects necessary to automate and improve the efficiency of the data construction pipeline .
Personally, I focus on designing data appropriate for each task , including the form of raw data and annotation methods optimized for model learning. I want to work with my team members to achieve this year's goals and make Upstage's Document AI shine even brighter!
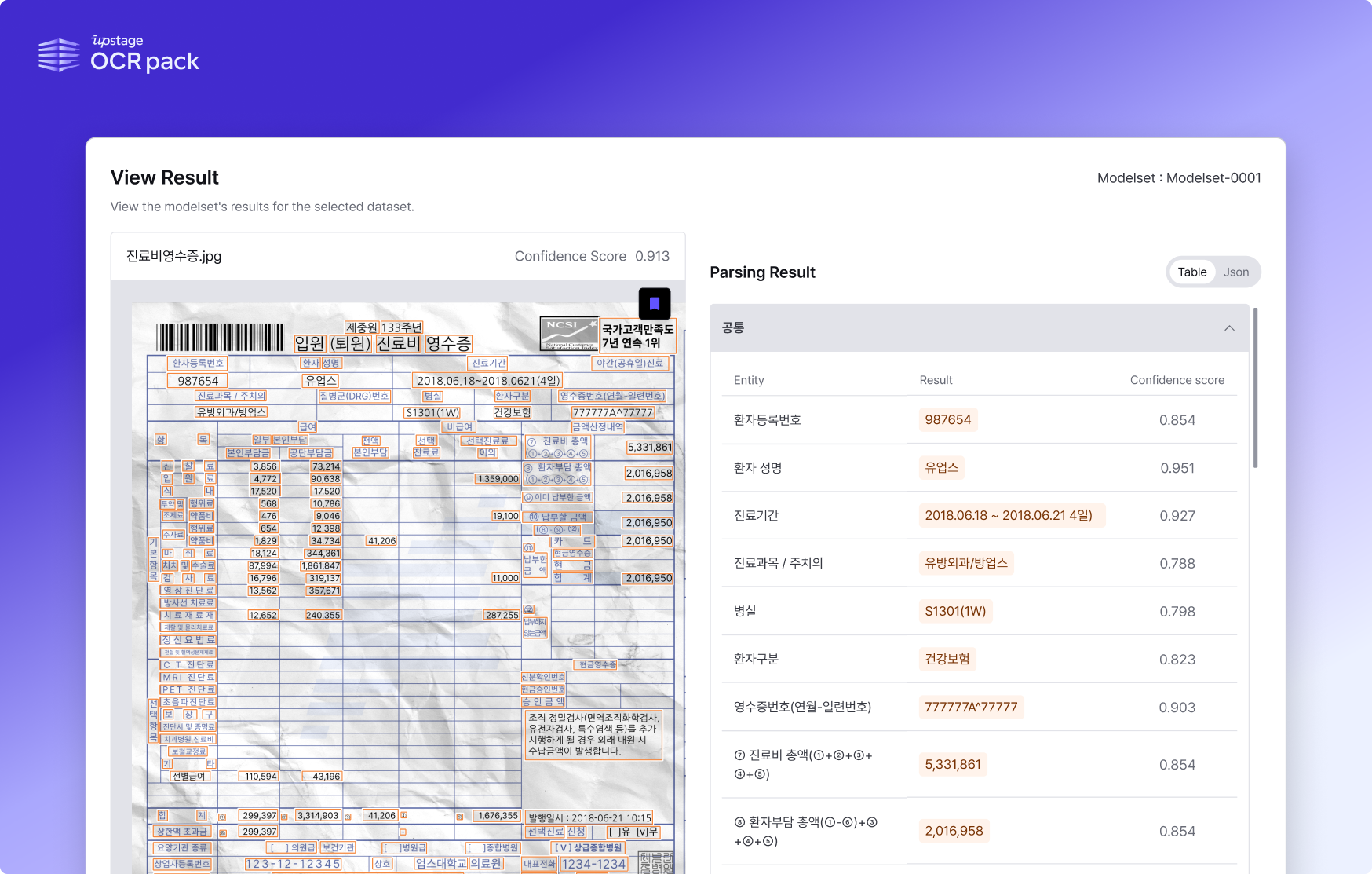
Demonstration scene of processing wrinkled or damaged medical bill receipts using Upstage's optical character recognition solution 'Document AI'
Event
Create new value through capitalizing data
Feel free to test the Document AI API in the Upstage console and create the service you want!
-
-
Upstage, founded in October 2020, offers a no-code/low-code solution called "Upstage AI Pack" to help clients innovate in AI. This solution applies the latest AI technologies to various industries in a customized manner. Upstage AI Pack includes OCR technology that extracts desired information from images, recommendation technology that considers customer information and product/service features, and natural language processing search technology that enables meaning-based search. By using the Upstage AI Pack, companies can easily utilize data processing, AI modeling, and metric management. They can also receive support for continuous updates, allowing them to use the latest AI technologies conveniently. Additionally, Upstage offers practical, AI-experienced training and a strong foundation in AI through an education content business. This helps cultivate differentiated professionals who can immediately contribute to AI business.
Led by top talents from global tech giants like Google, Apple, Amazon, Nvidia, Meta, and Naver, Upstage has established itself as a unique AI technology leader. The company has presented excellent papers at world-renowned AI conferences, such as NeurIPS, ICLR, CVPR, ECCV, WWW, CHI, and WSDM. In addition, Upstage is the only Korean company to have won double-digit gold medals in Kaggle competitions. CEO Sung Kim, an associate professor at Hong Kong University of Science and Technology, is a world-class AI guru who has received the ACM Sigsoft Distinguished Paper Award four times for his research on bug prediction and automatic source code generation. He is also well-known as a lecturer for "Deep Learning for Everyone," which has recorded over 7 million views on YouTube. Co-founders include CTO Hwal-suk Lee, who led Naver's Visual AI/OCR and achieved global success, and CSO Eun-jeong Park, who led the modelling of the world's best translation tool, Papago.