GPT Series And Development Process
2023/08/24 | 4mins
-
Hailey (Contents Communication)
* This content is 'ChatGPT UP for everyone!' produced by Upstage. It is written based on the contents of “GPT series and development process” during the lecture. -
Those who want to know about the language model
Those who are curious about the development process of the GPT model -
How did the GPT series develop until the birth of AI that develops day by day, ChatGPT, which is the most popular and widely known among them? It looks at the journey of about 5 years, from the concept of a basic language model to facing the ChatGPT era in recurrent neural networks (RNNs).
-
✔️ Language model
✔️ GPT SERIES AND EVOLUTION
✔️ Emergence (April 2017)
✔️ Transformer (June 2017)
✔️ GPT (JUNE 2018)
✔️ GPT-2 (FEBRUARY 2019)
✔️ “Emergence”: Zero-shot learning
✔️ GPT-3 (JUNE 2020)
✔️ “Emergence”: In-context learning
✔️ PRIOR TO GPT-4 RELEASE, 2021-2022
✔️ GPT-3.5 (MARCH 2022)
✔️ ChatGPT (November 2022)
(This content was written based on the contents of “GPT series and development process” in the lecture ' ChatGPT UP for Everyone' produced by Upstage .)
How did the GPT series develop until the birth of AI that develops day by day, ChatGPT, which is the most popular and widely known among them? It looks at the journey of about 5 years, from the concept of a basic language model to facing the ChatGPT era in recurrent neural networks (RNNs).
Language model
Generative Pre-trained Transformer (GPT) is a large-scale language model developed by OpenAI and used for various natural language processing tasks. For that reason, understanding the language model first can help you navigate the evolution of GPT. When a language model generates an answer, it usually solves it by guessing the next word . Let's take the problem below as an example.
Q. What is the correct word to fill in the blank?
”Today's participation in [ ] was difficult, but very rewarding.”
(1) Running
(2) nap
(3) Festival
The problem is figuring out what goes in the blanks. This approach applies to the language model as well. In this case, the advantage is that the model itself can generate countless correct answer data using the structure of words or sentences without requiring a human to generate correct answer data. Therefore, language modeling has the characteristics of self-supervised learning and can be considered advantageous for creating pre-trained models.

Recurrent Neural Networks (Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ )
In the early days of deep learning, language processing models were created as “RNN” architectures (the structure of the model and the frame of operations). RNN is a name given because the connections between nodes form a cycle, and it means a Recurrent Neural Network. Due to these characteristics, it is specialized in handling sequence-type data such as natural language .
Then, what is the background that developed ChatGPT from a simple next-word match like the example shown earlier?
GPT Series And Development Process
Emergence (April 2017)
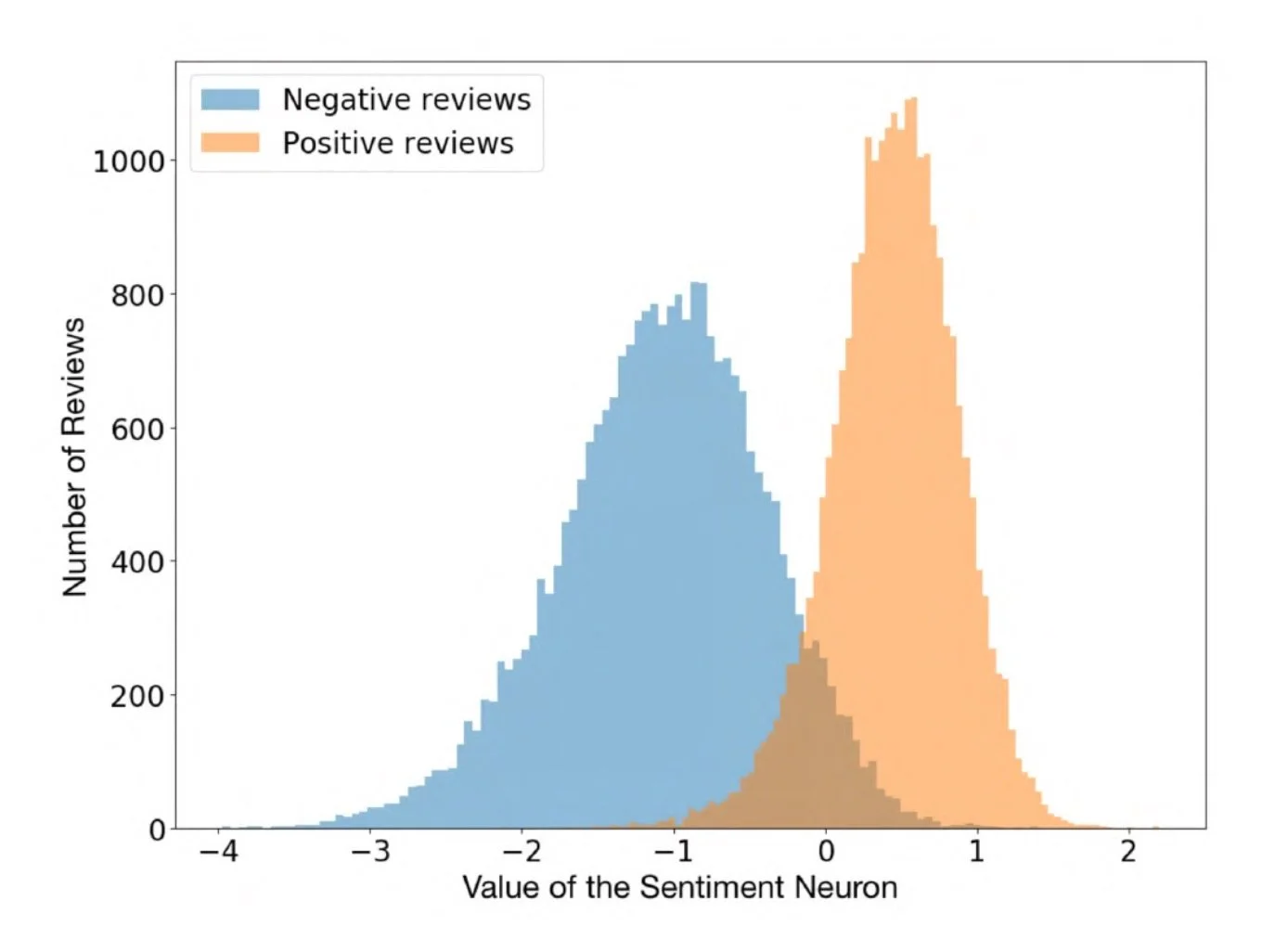
Sentiment neurons (Source: https://openai.com/research/unsupervised-sentiment-neuron)
In 2017, OpenAI was making its language model a Recurrent Neural Network (RNN). In this process, it is discovered that certain neurons are doing sentiment analysis. This leads to the hypothesis that unintended abilities are created in the language modeling process .
<감성 분석이란?>
The process of analyzing text content using artificial intelligence technology and judging emotions or opinions extracted from it
IT IS MAINLY DONE FOR TEXT DATA SUCH AS MOVIE REVIEWS AND ONLINE POSTINGS, AND AI UNDERSTANDS SENTENCES LIKE A HUMAN AND IDENTIFIES WHAT EMOTIONS ARE CONTAINED TO DISTINGUISH POSITIVE, NEGATIVE, NEUTRAL, ETC.
Transformer (June 2017)
In 2017, Transformer, a type of architecture similar to Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), appears. The core of this is an operation called 'Attention' , which indicates the relationship between items and items , and as a result, the Google Brain team's paper, “Attention is all you need,” emerged so important that it appeared. Since Transformer has better computational efficiency and result quality compared to existing RNNs, it has had a great influence to the extent that it has since become a technology used in all other fields such as vision, recommendation, and bio.
GPT (JUNE 2018)
A year later, the Generative Pre-training Transformer (GPT) first appeared. This can be understood as the creation of a language model in the self-supervised learning method described above. GPT is also considered a representative paper of the pretraining-finetuning paradigm , which is a finetuning process of creating a pretrained model through large-scale language modeling from the advent of GPT and learning this model with a small dataset suitable for each task. It is because it has been shown that it shows excellent performance in various NLP tasks.
<파인튜닝이란?>
The task of improving performance for a specific domain or task based on a pre-trained model
The key idea is that reusing pre-trained models using large datasets can reduce the model's training time on new tasks or domains and improve performance even when data is limited.
GPT-2 (FEBRUARY 2019)

GPT-2 is a version created by increasing the size of the existing model (117M → 1.5B) and increasing the amount of training data (4GB → 40GB). However, OpenAI judged that GPT-2, which has an excellent ability to generate, has a high risk of generating a large amount of fake information, so it was not disclosed to the outside world. GPT-2 showed emergence suggesting another influence as well as language-generating ability.
“Emergence”: Zero-shot learning
What new possibilities did the advent of GPT-2 reveal? This is the concept of “zero-shot learning” where the model performs a new task without ever seeing an example . These are also called Unsupervised multitask learners. Initially, it started as a language model, but several experiments were conducted to answer the question of whether it could perform various other tasks such as reading comprehension, translation, summarization, and Q&A.

As mentioned in the paper above, as the number of parameters (parameters) increases, the performance of zero-shot increases, and in certain tasks, it is better to outperform the existing SOTA (state-of-the-art) model. The singularity was that it was actually verifiable.
GPT-3 (JUNE 2020)
After confirming the various abilities of GPT through experiments like this, GPT-3, which appeared in 2020, increased in size once more. The model has grown from 1.5B to 175B, and data has also entered more than 600GB. Because we pretrained with more data than in the previous series, we have a more amazing generation ability. GPT-3 was also able to confirm emergence in several aspects, including the ability to “learn” tasks without knowledge and learning (few-shot learners). In the previous version, it only performed tasks, but now it shows the ability to learn tasks on its own.
“Emergence”: In-context learning
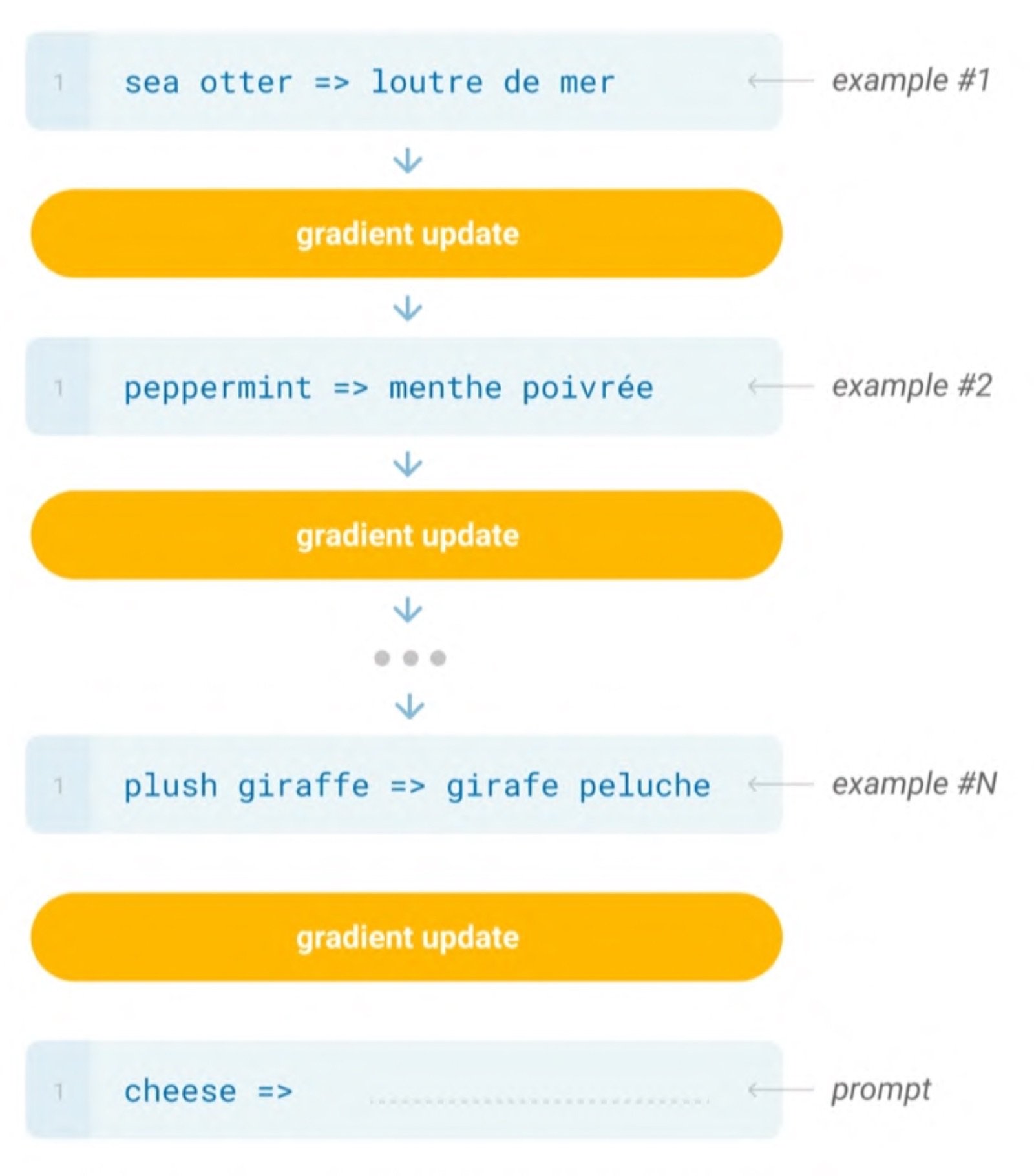
(Schematic of the fine-tuning process by inputting examples for each task into the model prior to in-context learning / Source: Language Models are Few-Shot Learners )
The emergence from GPT-3 is also called in-context learning. Before in-context learning, it was necessary to perform fine-tuning by inputting examples of tasks into the model. In this case, there was a limitation in that a model and data were required for each task, but starting with GPT-2, zero-shot learning became possible, and a new task could be performed without updating the model by putting a few examples (few-shot) in the prompt.
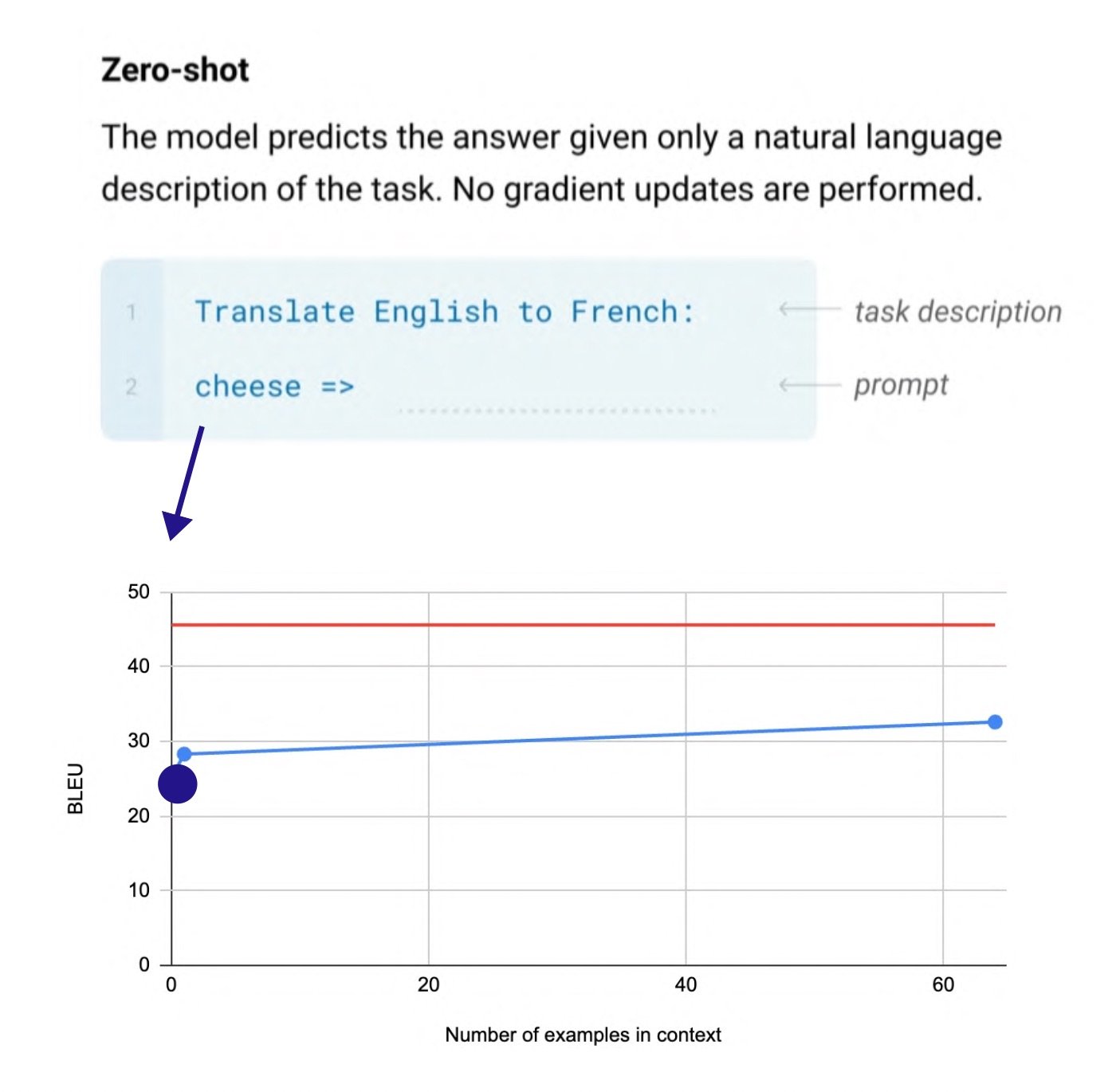
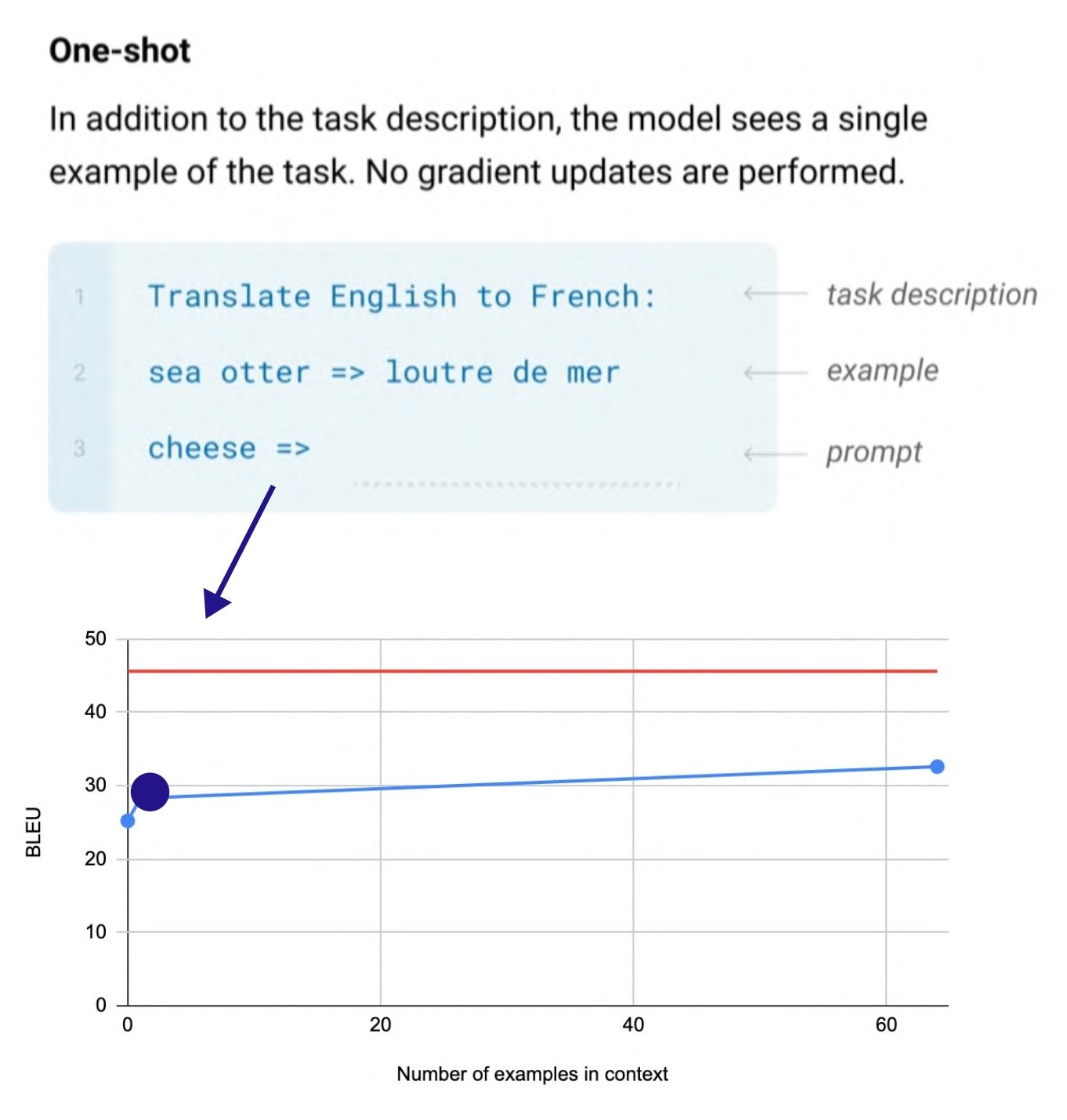
(Source: Language Models are Few-Shot Learners )
BEFORE GPT-4 RELEASE, 2021-2022
After GPT-3, people's anticipation for the release of GPT-4 grew. Prior to the official release of GPT-4, four noteworthy things appeared in the industry. CLIP and DALL-E, which are models that learn images as text, Codex for code generation, and InstructGPT, a language model that applies Instruction fine-tuning. Unlike the existing GPT, InstructGPT can give direct instructions to the model, and has received great attention as a language model designed to give answers tailored to the user's intention according to a series of instructions.
CLIP (January 2021): Classifying “zero-shot” images
DALL-E (January 2021): Create an image from given text
Codex (August 2021): Models for Code Generation
InstructGPT (January 2022)
: A model with fine-tuning and reinforcement learning for commands. If the existing GPT had to provide conditions or examples for the model to perform a specific task well through prompt engineering, InstructGPT generates the result as requested by the user with only simple natural language directives.<일반 언어 모델이 지시사항에 대해 생성한 내용>
💬 ”Tell me about ChatGPT”
→ EXPLAIN BERT / EXPLAIN GPT
<Instruction fine-tuning을 적용한 언어 모델이 지시사항에 대해 생성한 내용>
💬 ”Tell me about ChatGPT”
→ ChatGPT is one of the natural language processing models developed by OpenAI. This model is based on the Generative Pre-trained Transformer (GPT) architecture and is used as a dialog-based artificial intelligence model. ChatGPT is pre-trained with a large amount of data in advance, and then optimized through a fine-tuning process based on various conversation data. This allows ChatGPT to generate natural responses in conversations with users and converse on a variety of topics.
GPT-3.5 (MARCH 2022)
GPT-3.5 is a version with code data and Instruction fine-tuning added to GPT-3. According to the speculation of many researchers, it is not known whether this method directly affects the model, but it is observed that adding code data increases GPT's reasoning ability and understanding of long inputs.
In addition, Instruction fine-tuning is applied to GPT-3.5, and the experimental method of InstrctGPT (January 2022) is added, focusing on the fact that fine-tuning and reinforcement learning for commands better understands and responds to user intentions. there is.
ChatGPT (November 2022)
ChatGPT, which appeared in 2022, is one of the models that led to the popularization of AI. This is a fine-tuning of GPT-3.5, and in OpenAI, it is also called “sibling model” because the learning method is similar to InstructGPT.

Source: OpenAI Blog
Looking at the learning method of the ChatGPT model, the first step is to insert demonstration data consisting of instruction prompts and datasets. Here, the labeler labels actions that are considered appropriate for the instruction prompt, and the collected dataset is used to fine-tune GPT-3.5 through SFT (Supervised Fine Tuning) model learning.
In the next step, ChatGPT is updated with reinforcement learning (RL) using a reward model (RM) for user preferences. Through this method, ChatGPT can provide more diverse and flexible conversations.

Journey from RNN to ChatGPT
In this way, from RNN to ChatGPT, we looked at the long journey of the GPT series together. What are some of the moves toward Next GPT, the successor to ChatGPT? For more information on how ChatGPT will be used in the future and what various aspects will be needed for its development, you can check out the webinar replay page.
-
-
Upstage, founded in October 2020, offers a no-code/low-code solution called "Upstage AI Pack" to help clients innovate in AI. This solution applies the latest AI technologies to various industries in a customized manner. Upstage AI Pack includes OCR technology that extracts desired information from images, recommendation technology that considers customer information and product/service features, and natural language processing search technology that enables meaning-based search. By using the Upstage AI Pack, companies can easily utilize data processing, AI modeling, and metric management. They can also receive support for continuous updates, allowing them to use the latest AI technologies conveniently. Additionally, Upstage offers practical, AI-experienced training and a strong foundation in AI through an education content business. This helps cultivate differentiated professionals who can immediately contribute to AI business.
Led by top talents from global tech giants like Google, Apple, Amazon, Nvidia, Meta, and Naver, Upstage has established itself as a unique AI technology leader. The company has presented excellent papers at world-renowned AI conferences, such as NeurIPS, ICLR, CVPR, ECCV, WWW, CHI, and WSDM. In addition, Upstage is the only Korean company to have won double-digit gold medals in Kaggle competitions. CEO Sung Kim, an associate professor at Hong Kong University of Science and Technology, is a world-class AI guru who has received the ACM Sigsoft Distinguished Paper Award four times for his research on bug prediction and automatic source code generation. He is also well-known as a lecturer for "Deep Learning for Everyone," which has recorded over 7 million views on YouTube. Co-founders include CTO Hwal-suk Lee, who led Naver's Visual AI/OCR and achieved global success, and CSO Eun-jeong Park, who led the modelling of the world's best translation tool, Papago.