Developing a service-oriented AI model Ep.2 Preparing a training dataset for developing an AI model
2022/03/04⏱ 15mins -
Tal- Seok Lee (Upstage CTO)
(Former) Visual AI/OCR Head of Naver Clova, (Current) CTO & AI Research Engineer at Upstage
Jamie (Content Marketer)
-
THOSE WHO ARE CURIOUS ABOUT THE BEST AI COMPANY'S CUSTOMER-ORIENTED AI MODEL DEVELOPMENT METHODS AND SPECIFIC TASKS
-
Ep. Check out 2 for the first steps to developing a service-oriented AI model, how to prepare a training dataset and how to create it.
-
✔️ Build training datasets from service requirements
✔️Type and quantity of training dataset
1. Refine the type of training dataset
2. Refine the type and quantity of the training dataset
✔️ Design the correct answer and technical module of the learning dataset
1. Design the technology module
2. The correct answer in the training dataset
3. BUILD TRAINING DATASET AND DESIGN AI MODEL STRUCTURE
✔️Create training dataset

EP.2 INTRODUCTION
hello. Developing Service-oriented AI Model EP. 1 , we investigated what conditions change when the AI model development environment is different. In the research environment, it was confirmed that the training dataset and the test dataset are controlled environments, whereas in the actual field, only the service requirements of the customer exist and there may not be the training dataset and the test dataset. This difference is a major factor that makes AI modeling more difficult in the real world.
In EP.2, we will look at how to prepare the 💡 'training dataset' , which is essential for AI model development. If there is no given training dataset, such as a research environment, what path and hint can we obtain data through? The answer is your customer's service requirements . So, let's see how the service requirements become a hint to build the training dataset, and what process the training dataset is created through.
Building a training dataset from service requirements
THE FIRST STEP IN DEVELOPING A SERVICE-ORIENTED AI MODEL IS 'PREPARING THE TRAINING DATASET'.
More precisely, it is defining the ✔️ kind, ✔️ quantity, and ✔️ correct answer for the training dataset . One clue is given to define these three. That is the customer's service requirements .

[Figure 1] Preparing a training dataset based on service requirements
THE AI TECH TEAM NEEDS TO FIGURE OUT WHICH SERVICES THE AI MODEL WILL INTRODUCE FROM THE SERVICE REQUIREMENTS. THE AI TECHNICAL TEAM REFINES THE REQUIREMENTS FOR THE SERVICE PLANNING TEAM AND THE AI MODEL IN CONSIDERATION OF THE CUSTOMER'S REQUIREMENTS AND RESTRICTIONS. THE ELEMENTS THAT NEED TO BE SPECIFIED FIRST AMONG THOSE REQUIREMENTS RELATE TO THE 'TRAINING DATASET'. THE TRAINING DATASET INVOLVES SEVERAL STAGES OF THE BUILDING PROCESS, WHICH WE WILL EXPLAIN ONE BY ONE. SO LET'S FIRST LOOK AT HOW TO DEFINE THE ✔️KINDS AND ✔️QUANTITIES OF OUR TRAINING DATASET.
Type and quantity of training dataset
1. Refine the type of training dataset
LET'S SAY THAT THE CUSTOMER'S REQUIREMENT IS "DEVELOP A TECHNOLOGY THAT RECOGNIZES FORMULAS BY TAKING PICTURES." THE SERVICE PLANNING TEAM FORWARDS THESE REQUIREMENTS TO THE AI TECHNICAL TEAM. AFTER THAT, THE TWO TEAMS LEARN WHICH TRAINING DATASET FROM THE SERVICE REQUIREMENTS. WE'LL DISCUSS WHETHER TO COLLECT THEM, SO LET'S TAKE A QUERY EXAMPLE BELOW TO MAKE THIS PROCESS A LITTLE EASIER
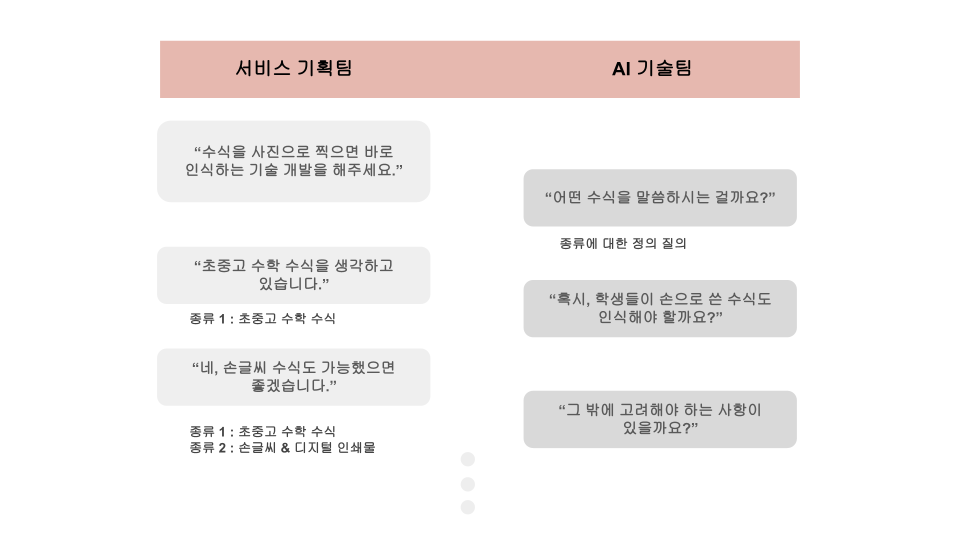
[FIGURE 2] COMMUNICATION BETWEEN AI TECHNOLOGY TEAM AND SERVICE PLANNING TEAM
THE REQUIREMENTS SPECIFIED THROUGH COMMUNICATION BETWEEN THE SERVICE PLANNING TEAM AND THE AI TECHNOLOGY TEAM WILL BE AS FOLLOWS.
“ It is necessary to develop a service in which AI enters formula values into computers on behalf of students when formulas at elementary, middle and high school math levels are handwritten or printed on paper.”
2. Refine the type and quantity of the training dataset
THROUGH THE ABOVE QUERY PROCESS, A SPECIFIC GOAL OF 'DEVELOPMENT OF A SERVICE THAT CAN INPUT FORMULAS WITH AI INSTEAD OF STUDENTS' WAS SET.
TO ACHIEVE THIS GOAL, THE AI TECH TEAM WILL NEED TO DETERMINE THE ✔️TYPE AND ✔️QUANTITY OF DATA TO COLLECT. THE AI TECHNICAL TEAM ONLY NEEDS TO COLLECT APPROPRIATE DATA BASED ON THE PRIMARY GUIDELINES AS SHOWN IN [FIGURE 3] BELOW.
✔️ Type : Level (elementary, middle, high school) X Source (print, handwriting)
✔️ Quantity : n pieces each
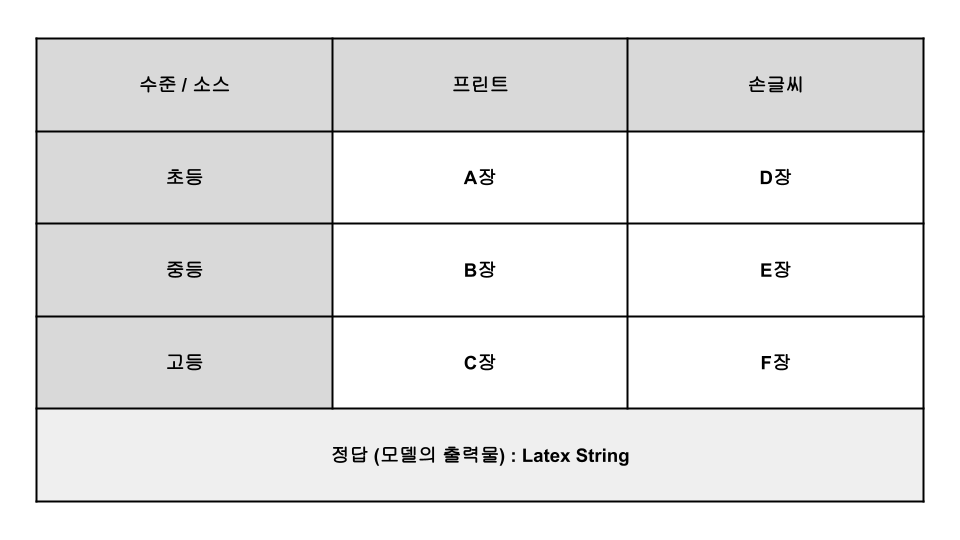
[Figure 3] Guidelines for building a training dataset
📍 What situations do you need to consider when setting guidelines?
👉 IT IS NECESSARY TO CLEARLY DEFINE THE 'KIND' OF THE DATA. AS IN THE GUIDELINE EXAMPLE ABOVE, CONSIDER HOW TO DIVIDE THE TYPES OF LEVELS, SOURCES, ETC. AFTER THAT, THE 'QUANTITY' OF DATA TO BE COLLECTED FOR EACH DATASET SHOULD BE DETERMINED BY COMPREHENSIVELY CONSIDERING THE MODEL SIZE, BUDGET, AND WORKING PERIOD. IN ADDITION, VARIOUS 'TYPES' CAN BE CONSIDERED UNDER THE ASSUMPTION THAT AN AI FORMULA DETECTION MODEL IS CREATED. ASSUMING A VARIETY OF SITUATIONS, SUCH AS A CLEAN IMAGE WITHOUT NOISE, SHADOWS, EQUATION ROTATION, AND CROPPED EQUATIONS, BETTER RESULTS CAN BE DELIVERED WHEN APPLIED TO ACTUAL SERVICES. ACCORDING TO THIS KIND OF CLASSIFICATION, YOU ALSO NEED TO DETERMINE THE QUANTITY.
📍 Are there any variables in the data collection process?
👉 UNEXPECTED VARIABLES OFTEN OCCUR WHEN SETTING GUIDELINES IN THE DATA COLLECTION PROCESS. FOR EXAMPLE, YOU MIGHT HAVE MULTIPLE FORMULAS WITHIN A SINGLE IMAGE. IN THIS CASE, THE AI TECHNICAL TEAM AND THE SERVICE PLANNING TEAM SHOULD DISCUSS AND REVISE THE DATA SET COLLECTION CRITERIA.
This is because, in terms of image acquisition efficiency and scenarios, allowing extraction of multiple equations from one image can be more efficient than allowing only one equation from one image. Of course, in order to capture multiple equations in one image at the same time, it is necessary to further develop a technical model that detects the 'arithmetic area'. Therefore, it is essential to set the scope of data collection considering various factors such as service experience point of view, total resources for data creation, and development of additional technology modules.

[Figure 4] Variables in the data collection process (when multiple formulas are taken at the same time)
Design of the correct answer and technical module of the training dataset
1. Design the technology module
Once you have decided on the type and quantity of the training dataset, ✔️ Introduce it to the design stage of the technology module . The technical module design is a useful and important clue to precisely define the ✔️ correct answer of the required training dataset for each module.
Let's return to the example of formula recognition. In the scenario of processing a single equation, only images corresponding to one equation will be entered into the technology module. Without detecting a separate formula area, the content of the formula image can be output as the correct answer (Latex String). Then, as shown in [Figure 5], an input/output type of technology can be designed.
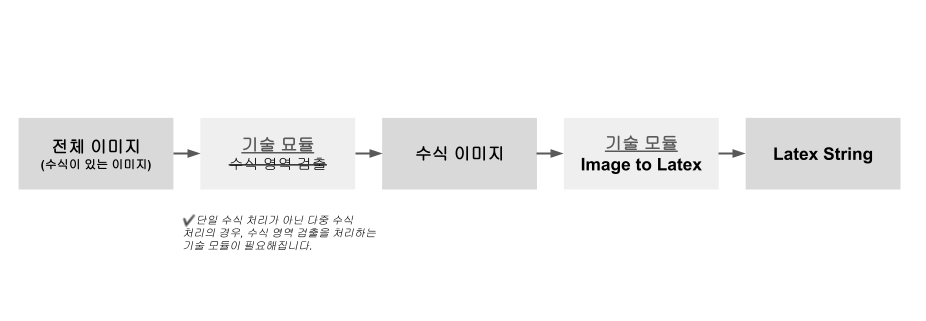
[Figure 5] Input/output process of correct answer in training dataset of single formula recognition scenario
So, what about scenarios that deal with multiple formulas? A technology module should be further developed in which the positions of multiple mathematical regions in the entire image are all 'modified region detection'.
2. The correct answer in the training dataset
✔️ The correct answer in the training dataset is the output of each skill module. In the 'Equation Area Detection' technology module in [Figure 5], the 'correct answer' of the training dataset is the location of the formula areas. The position values of the formula area may vary depending on how the 'Formula Area' is defined. For example, if an equation is displayed in a rectangular shape, the position of the equation area can be indicated through the position values of the upper-left and lower-right points. This is the 'correct answer' of the Mathematical Area Detection Technology module.
(1) Rectangle in [Figure 6]: Please refer to 2 dots.
As another example, it is possible to express area information in units of pixels rather than dots. I will display the part corresponding to the formula area with a value of 1, and the part that does not correspond with a value of 0. At this time, the formula area detection module performs a kind of segmentation task, and the result of Image Segmentation becomes the 'correct answer'.
Please refer to (4) pixel unit area in [Figure 6].
(1) (2) (3) (4).. AND COUNTLESS OTHER DEFINITIONS CAN BE FOUND. THIS DEFINITION OF 'CORRECT ANSWER' SHOULD BE DETERMINED BY CONSIDERING THE OPTIMAL METHOD FOR OBTAINING THE BEST RESULTS FOR EACH AI MODEL.

[Figure 6] Input/output process of correct answer in training dataset of multi-formula recognition scenario
3. THE RELATIONSHIP BETWEEN BUILDING A TRAINING DATASET AND DESIGNING AN AI MODEL STRUCTURE
The process of building the training dataset, which has been working hard so far, is intertwined with the 'design area of the AI model structure' . The reason is that a certain level of training dataset is required to validate the AI model design. You need to validate the model trained on the data to determine if the model design you've devised for your service needs and limitations is being done.
Therefore, in the field, it is interlocked with ' training dataset collection ' and ' AI model design '. Rather than designing the training dataset and model independently, it is carried out through discussion and cooperation between relevant departments (service planning team, modeler, training data manager, etc.).

[FIGURE 7] RELATIONSHIP BETWEEN TRAINING DATASET CONSTRUCTION AND AI MODEL DESIGN
Create a training dataset
A service planner and an AI model developer have determined the ✔️type, ✔️quantity, and ✔️correct answer for a training dataset. Then, the training data set preparation staff will start preparing for the training data production in earnest based on the discussions so far. Are you curious about who makes the training data? In some cases, data is created directly by our own people. However, most companies today outsource this process to outsourced companies.
At this time, it is necessary to prepare an Annotation Guideline containing information on the type, quantity, and correct answer of the training dataset. A specific and clear guideline must be given so that the outsourcing company can introduce it to data production based on the guideline.
When deciding on a subcontractor, we consider the work period and unit cost required for data production together. These influence the type of training dataset, its quantity, and the degree to which it defines the correct answer. For example, if the formula area is a rectangle, it may be a task to derive the correct answer for two points, but if it is an arbitrary rectangle, it will have to work for four points. This inevitably increases the production period and unit cost.
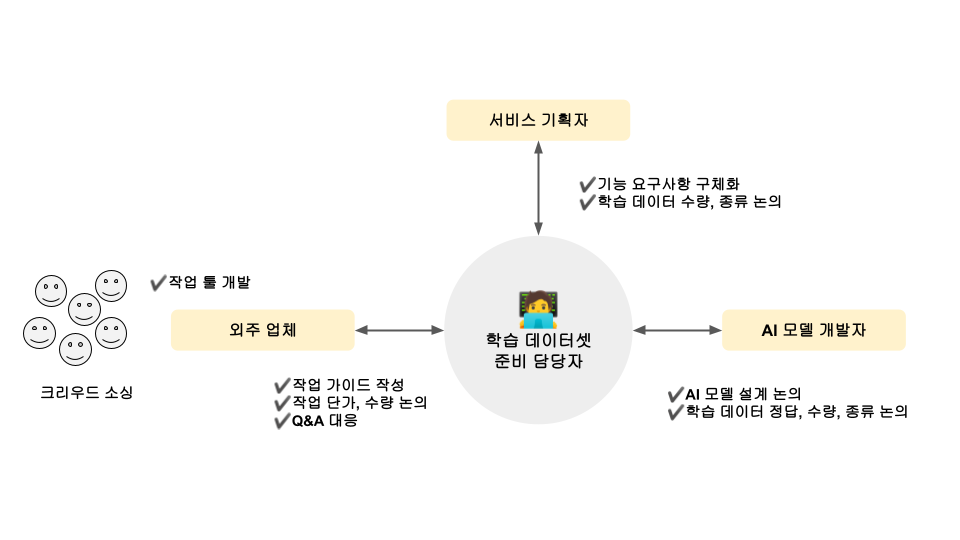
[Figure 8] Communication process of the person in charge of preparing the training dataset
EP.2 GOING OUT
SO FAR, WE HAVE LOOKED AT THE PROCESS OF PREPARING AND PRODUCING A TRAINING DATASET FOR SERVICE-ORIENTED AI MODEL DEVELOPMENT. IT WAS TO DEFINE THE TYPE, QUANTITY, AND CORRECT ANSWER OF THE TRAINING DATASET FROM THE CUSTOMER'S SERVICE REQUIREMENTS, AND THEN START BUILDING THE TRAINING DATA BASED ON THIS. WE HOPE THIS EPISODE HAS HELPED YOU GAIN A BETTER UNDERSTANDING OF THE AI MODEL DEVELOPMENT PROCESS.

[Figure 9] Training data set preparation process at a glance
IN THE NEXT EP.3, WE WILL FIND THE TEST METHOD TO EVALUATE THE AI MODEL FROM THE CUSTOMER'S SERVICE REQUIREMENTS, HOW TO DEFINE THE TEST DATASET, AND HOW TO DERIVE THE REQUIREMENTS OF THE AI MODEL. THANK YOU
-
Upstage is a global AI company that makes the world a better place with AI. Upstage provides AI Pack (AI solution) for business success of customers based on the world's best AI technology and know-how. AI Pack supports customer AI innovation as well as solving various business problems centered on OCR Pack and Recommender System Pack. Upstage puts customers on the world stage with AI technology.